
If you hang out in startup circles like I do, then you may have heard of the “Learn Startup” methodology. But what is it exactly? I’ve been researching Lean Startup and in this blog post I will summarize what I’ve learned, explain what new insights this research has given me, and talk about future research and blogging directions.
Featured posts

Who's responsible for the software we build?
Turns out running a company isn’t just about money, fame or even cool products and happy customers. We have a social responsibility towards our employees and society at large.

How to build a good company purpose?
It has often been stated by business consultants and startup advisors that a company should have a purpose beyond vision. Studies show that that result in more motivated and loyal customers and employees. As Simon Sinek said: people don’t buy or follow what you do, but why you do it.
I agree. That was the easy part. But how do you actually define a good purpose? People need to feel that your purpose is aligned with their own values, and a purpose statement needs to balance many different things for many different people.
This post documents the start of my journey in an attempt to find answers.

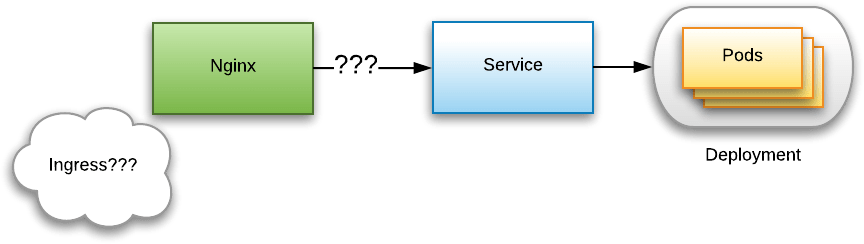
Studying the Kubernetes Ingress system
I have been researching how the Kubernetes Ingress system works. My use case is to setup an autoscaled Nginx cluster that reverse proxies to Pods in multiple Deployments. It wasn’t immediately obvious how to do this. By default, Pods in Kubernetes are not supposed to be reachable from outside the cluster. One makes them reachable either by associating those pods with a Service of the right type (i.e. either NodePort or LoadBalancer), or by defining an Ingress. But what is an Ingress? How do I put Nginx in between an Ingress and a set of Pods? This post describes my journey through the jargon-loaded Kubernetes documentation which does not hold any hands, as well as my journey through the Kubernetes source code, all in a quest to find answers.
This post a bit long, so if you just want a summary then you can skip straight to the conclusion at the bottom.

In appreciation of Prometheus' engineering
Even though I rejected Prometheus as a choice in my last blog post about Netdata, I actually appreciate Prometheus’ engineering quality. From its documentation it is apparent that the authors are very experienced on the subject and have thought through things.
This post reviews some of the things that demonstrate that, namely their responses to the push vs pull debacle, the way they limit Prometheus’ scope, the way their alerting system is designed and documented, and the way they treat storage.
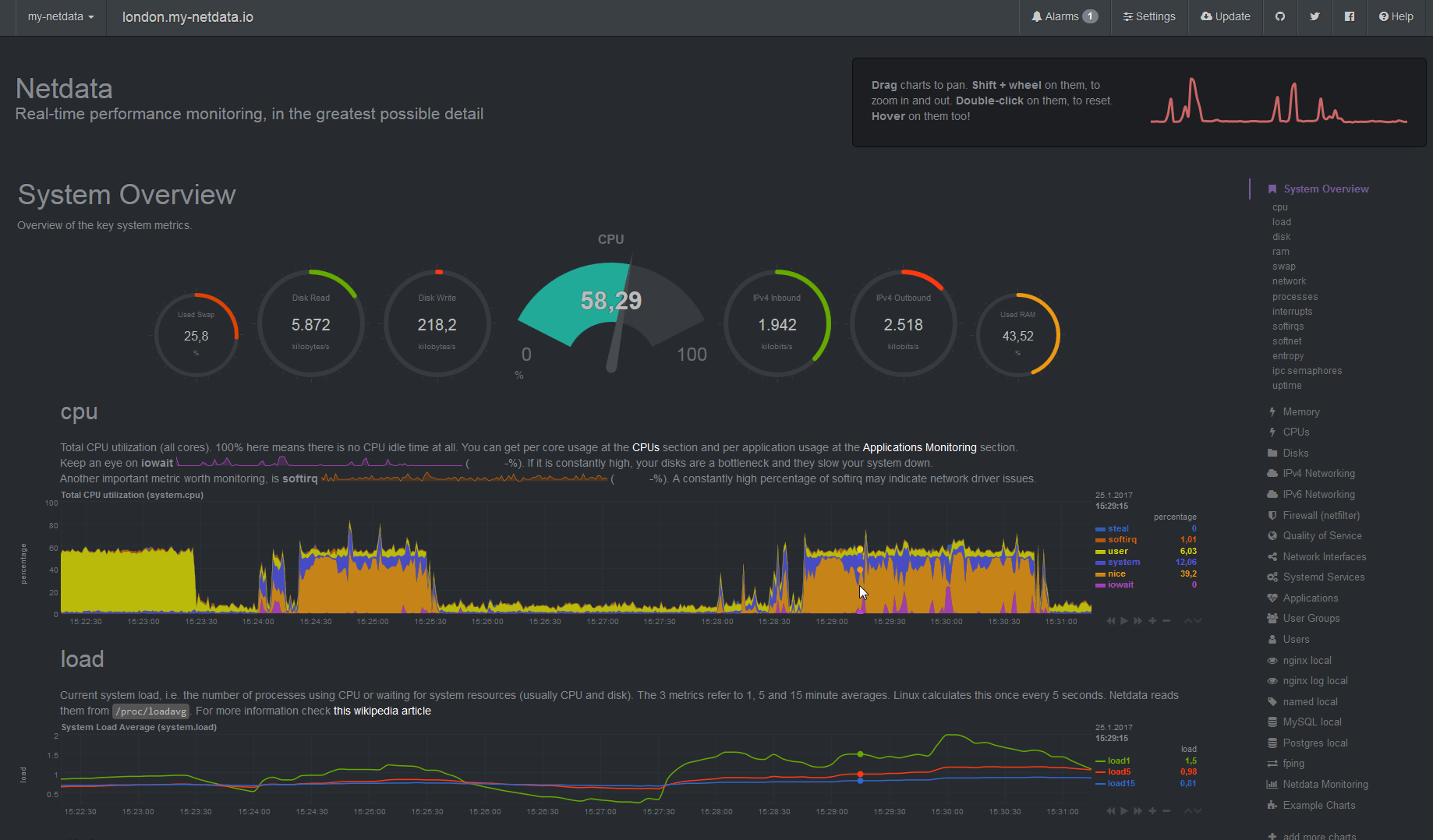
Netdata: simple server monitoring
I have been looking for an easy-to-use monitoring solution for Phusion’s servers. One that does not require a lot of setup and that provides a reasonable interface without too much work. Such a solution has to display a bunch of graphs at the very least. (Email) alerting is considered a bonus. The solution also has to be open source, not only because of the cost factor but because I want to own my data. So solutions like New Relic and Datadog are out.
In this blog post I will describe the solutions that I’ve checked out – Ganglia, Monit, Munin, Prometheus, Grafana – and why I didn’t like them. Then I will explain why I think Netdata is a good choice and review its pros and cons.
Understanding your benchmarks and easy tips for fixing them
Update August 9: urikanegun has kindly contributed a Japanese translation of this article.
Developers love speed, so developers love benchmarks. Benchmarks on programming language performance, app server performance, JavaScript engine performance, etc. have always attracted a lot of attention. However, there are lots of caveats involved in running a good benchmark. One of those caveats is benchmark stability: if you run a benchmark multiple times then the timings usually differ a bit. A a lot of people have the tendency to hand-wave this caveat by just shutting down all apps, rerunning the benchmark a few times and averaging the results. Is that truly good enough?
Lately, I have been researching the topic of benchmark stability because I am interested in creating reliable benchmarks that are reproducible by third parties, so that they can verify benchmark results by themselves — e.g. allowing users of my software to verify that my benchmarks are reliable. Such research has led me to Victor Stinner, a Python core developer who has been focusing on improving Python 3 performance for several years.